

Picture your company’s data—decades of insights trapped in disparate PDFs, recordings, and email threads. AI models are transforming nearly every aspect of business, but the real hurdle isn’t building the models. It’s making sure you have the right data to power them. And you’re not alone. Despite the plethora of tools and models available, data leaders still struggle to get a clear view of their data landscape.
For MLtwist founder David Smith, this wasn't just a market opportunity; it was a huge gap he’d seen throughout his career at Google and Oracle. "The ecosystem is powerful, but everything operates in silos," Smith explains. “While others focused on the AI models, we focused on one thing: getting data ready for AI.”
And that has paid off. As AI continues to explode, the demand for better data preparation has grown just as fast. For many companies, data prep goes beyond just being another step in the process—the complexity of preparing and cleaning data slows down the development and integration of AI tools and, therefore, results.
That’s where MLtwist comes in. Think of it as the refinery that turns the crude oil of raw data into the high-octane gas of clean, structured data to fuel AI models.
How MLtwist Works
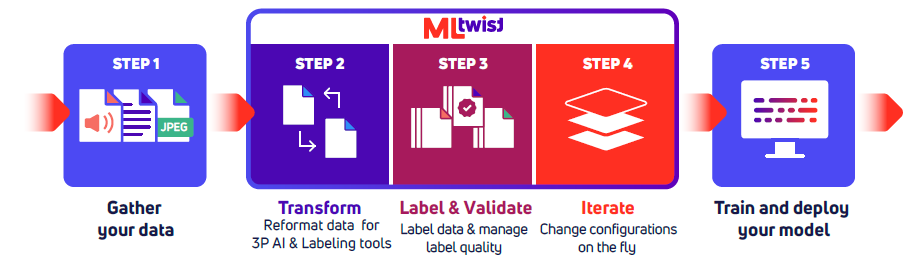
MLtwist scales data preparation across enterprises with high-stakes, high-frequency needs through a three-step process:
- Data Ingestion: Connecting directly to raw data sources—from enterprise systems to research repositories.
- Data Transformation: Combining automated processing with targeted human validation.
- Delivery of AI-Ready Data: Producing polished, structured datasets ready for AI consumption.
Scaling Security: How MLtwist Powers AI-Driven Innovation for the TSA
MLtwist is putting this technology to work in an area that touches millions of lives daily: airport security. In a July 2024 webinar hosted by  Carasoft, Andrew Cox from Sandia National Laboratories explained their mission: "TSA needs to detect when someone attempts to bring prohibited items through checkpoints. But to build those AI detection systems, you need a massive amount of properly labeled scan data—and that’s where the real challenge begins."
Carasoft, Andrew Cox from Sandia National Laboratories explained their mission: "TSA needs to detect when someone attempts to bring prohibited items through checkpoints. But to build those AI detection systems, you need a massive amount of properly labeled scan data—and that’s where the real challenge begins."
Working with Sandia National Laboratories, MLtwist helped transform TSA security scan data for AI applications. The stakes are high: every mislabeled scan or data error could impact threat detection accuracy. What started as a simple process turned into managing over 75 different error points in Sandia’s pipeline. But with MLtwist's help, Sandia was able to cut data preparation time from several months to just a few weeks.
Enterprise AI: Unlocking Data Value at Scale
Companies are using MLtwist to analyze customer calls for churn signals, process video feeds for quality control, enhance lead scoring with unstructured data, and personalize content based on customer interactions. In financial services, MLtwist can help process complex documentation for compliance. The platform can also support healthcare organizations in structuring patient feedback and clinical notes, while manufacturers can leverage it for automated quality inspections.
But in today’s market, having great tech isn’t enough. MLtwist needed to cut through the noise in a way that would catch enterprise buyers’ attention. That’s where Stage 2 Capital’s Catalyst program and its network of GTM experts made a difference.
Jake Makler, AI Consulting Practice Lead at IBM, worked closely with MLtwist to refine its go-to-market strategy, sales positioning, and enterprise partnership framework. With extensive experience helping companies scale AI solutions, Makler knew firsthand how enterprises struggle with the inefficiencies of preparing unstructured data for AI.
“Enterprises investing in AI often underestimate the true bottleneck—pre- and post-processing inefficiencies that consume up to 80% of a data scientist’s time,” Makler explains. “MLtwist eliminates that friction by automating labeling and pre-processing, ensuring AI models are production-ready within tight 3-month cycles.”
Creating A Category of Its Own
With the foundational strategy in place, MLtwist also needed a GTM approach that helped buyers sort through the noisy AI market.
Brian Goldstein, GM of Data, Analytics & AI at Google, worked alongside the team to refine how they communicated their value proposition to enterprise customers. At the same time, Nick Tippmann, former CMO of Greenlight Guru, challenged MLtwist to think bigger.
“Rather than just pushing more top-of-funnel efforts, I recommended they first run a category creation and positioning exercise to clearly articulate why they were different, not just better,” Tippmann shares.
Once they nailed their story, they turned it into the Ultimate Guide to AI Data Pipelines—a cornerstone asset that not only drives top-of-funnel leads but also plays a critical role in educating the market.
Preparing the Future: What’s Next?
As MLtwist looks to the future, it’s focusing on doing what it does best: helping companies turn unstructured data into AI-ready insights. The team continues to refine its own internal models and AI to proactively respond to new use cases, customer needs, and emerging regulations like the EU’s AI Act.
“We’ve always believed that solving unstructured data challenges is a rising tide that lifts all ships,” says David Smith. “And we’re just getting started.”